One-box stream processing with CSP
A simple streaming data architecture using clojure.core.async
If you’re like me (that is, employed by an ad tech company), stream processing is usually associated with frameworks like Storm, Flink, Spark Streaming, and other such solutions. However, a lot of real-life software can be described as stream processing – data comes in one end, is transformed or aggregated, and goes somewhere else. Many of these workloads don’t justify the overhead of a stream processor, but that doesn’t mean they can’t benefit from some of the lessons of stream processing systems.
In this article I’ll be going into detail of a small-scale stream-processing architecture for Clojure, built around the core.async and component libraries. This architecture allows us to build modular components connected entirely by asynchronous queues, allowing for very flexible systems. The lessons herein can also be broadly applied to other coroutine systems in other languages, such as Go and Kotlin.
Motivation
Existing stream-processing architectures concern themselves extensively with problems that arise from distributed computing: ensuring that datapoints are processed at least/exactly once and generally handling the distribution of datapoints to nodes and processes within them. Most such systems promote a similar architecture, wherein you are reponsible for defining components to transform incoming datapoints, which match the system’s API regarding incoming and outgoing data, and with assembling those components into your final system.
The basic principles of designing a system based on stream-based CSP are quite similar; you have various processes, which are connected to each other via channels, which act as queues. Even if we’re not writing a distributed system, approaching a streaming-data system from this angle can provide us some benefits. Specifically, we will be forced to develop reusable components which are loosely coupled (in this case, via core.async channels).
Later, if we want to make design changes – a simple example would be adding persistent queues between components – we can completely reuse the existing components, and need only adapt the external service to a core.async channel.
CSP with core.async
Clojure’s core.async is inspired by Go’s Concurrent Sequential Processing features. It
allows you to structure your program as a serious of asynchronous state machines, which
can logically block waiting for each other without holding a thread while they do it.
This is called parking, and it can help simplify highly-concurrent workloads substantially.
I’ll be quickly reviewing Clojure’s implementation here, but if you’re not familiar with
the subject, Brave Clojure has a great primer you should read.
The basic unit of a core.async workflow is a channel. A channel behaves like a queue –
items can be put to it, or taken to it, and will retain the order that they were placed
on the queue. Outside of a go block, you can asynchronously (with a callback) put! to
or take! from a channel, or you can synchronously (blocking a thread) put (>!!) or
take (<!!) from it:
(require '[clojure.core.async :as a])
(def mychan (a/chan))
; Asynchronous take
(a/take! mychan prn)
; Blocking put (callback will be invoked)
(a/>!! mychan :test)
To use the “parking” feature, you can use the go macro, wherein the parking
put >! and take <! can be used:
; Parking take
(a/go (prn (a/<! my-chan)))
; Parking put
(a/go (a/>! my-chan :test2))
The go macro will, effectively, rewrite its contents into an event-driven state
machine, allowing channel operations to wait for responses without holding up a thread.
A single machine can easily handle thousands (or more) of parking operations
(and therefore go blocks) simultaneously. The contents of a go block are sometimes
said to be run in an “Inversion of Control” (IOC) thread.
Channels can be closed; takes on closed channels will return the contents of the
buffer until it is empty and nil thereafter (NB that nils cannot be placed on
a channel on purpose, and therefore always signify a closed channel). Puts to
closed channels will complete immediately and cause >!! and friends to return false,
signifying that the put failed.
Buffered channels
By default, channels are unbuffered, and attempts to put to a channel will block until some other process is ready to take from it. This is an extremely useful property, since it allows us to build in back-pressure. However, sometimes it can be useful to have channels store message – this allows processes putting to those channels to proceed without waiting for the message to be taken.
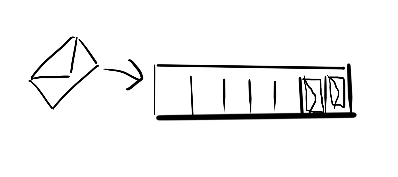
A fixed buffer of size n will allow n items to be put to the channel and stored. If the buffer is full, puts will block. If you don’t mind losing some messages and want to make sure your source process can continue unimpeded, you have your choice of sliding or dropping buffers.
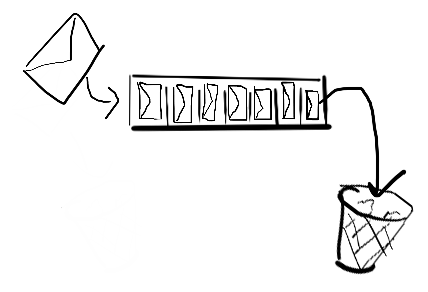
A sliding buffer, when full, will remove the least recent message (i.e. the next message that would be taken from the channel):
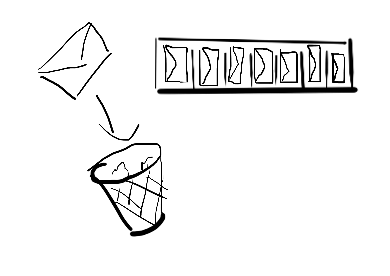
A dropping buffer will allow puts when full, but discard the message:
Here’s how to create channels with different buffer types
(def fix-chan (a/chan (a/fixed-buffer 2)))
(def fix-chan2 (a/chan 2)) ; Creates a fixed buffer by default
(def drop-chan (a/chan (a/dropping-buffer 2)))
(def slide-chan (a/chan (a/sliding-buffer 2)))
Transducers
Transducers are a utility devised to generalize collection operations. There is a lot to know about transducers, but for our purposes, what you need to know is that channels can be created with attached transducers, which means that their content will be transformed automatically as it passes through the channel:
(def xform (map clojure.string/upper-case))
(def scream-chan (a/chan 1 xform))
(a/put! scream-chan "hello")
(a/<!! scream-chan) ; "HELLO"
Since transducers can be applied generally, to collections as well as channels (try (eduction xform ["hello"])),
they are easy to write and test.
Splitting and combining channels
It’s straightforward to pipe one channel to another:
(a/pipe in-chan out-chan)
By default, pipe will
automatically close out-chan if in-chan is closed. See also pipeline, which does the same but
multithreaded and with a transducer. See also pipeline, which can apply a transducer and add parallellism.
Many-to-one many-to-one channels are easy enough; just put to a channel from one or more
sources (or use merge).
Sometimes, however, you will have more than one process consuming from the same input stream. In this
case, you can use core.async’s built-in mult/tap functionality.
You can use mult to create a mult – that is, a quasi-channel that can be consumed by
more than one consumer. Every mult has a single backing channel; writes to that channel will
be distributed synchronously to all taps. When using mult, remember that no other process
should consume from the backing channel – otherwise you’ll have a read race and the mult may not
receive other messages.
(def c (line-chan "myfile.txt"))
(def c-mult (a/mult c))
To add a consumer to a mult, use tap:
; tap returns the channel, so you can do this:
(def out-c (a/tap c-mult (a/chan)))
(a/put! c-mult "hello")
(a/<!! out-c) ; "hello"
Other solutions for multiple-channel designs are pub and mix; you can read
more about these in the docs.
Designing an application
The basic principles of designing a system based on stream-based CSP are quite simple; you have various processes, which are connected to each other via channels, which act as basic queues.
How work is divided between the processes can be important; as a rule, remember that go blocks are cheap but not free.
Sources and sinks
Unless you have extremely good luck, the entry and exit points of your pipeline will not
be native core.async channels, and so you’ll have write your own adapter.
The following function will open a file and put the contents into a channel that it returns.
(defn line-chan [filename]
(let [out-chan (a/chan)] ; 1
(a/thread ; 2
(with-open [f (io/reader filename)]
(try
(doseq [line (line-seq f)]
(a/>!! out-chan line)) ; 3
(finally ; 4
(a/close! out-chan)))))
out-chan ; 5
))
Note the use of an unbuffered channel. This will cause the later
>!!operation to block until each line is taken from it. A fixed buffer may be used if you like; however, a sliding or dropping buffer would just immediately consume the file and drop most of the records.Here,
theadis used instead ofgo. Allgoblocks in your program (or at least those in a single running Java process) use a shared thread pool. For this reason, it’s usually advisable to usethreadinstead ofgo, to avoid using up a thread fromgo’s thread pool on non-parking i/o.Since we’re not inside of a
goblock, we must use>!!instead of>!.It is generally not a big problem if you don’t close a channel, but you should endeavour to do so for the sake of building good habits if nothing else.
Remember to return the output channel!
Intermediate processes
Most of your intermediate processes will use go-loop to consume indefinitely from
a channel. I’ve found that this basic pattern is generally useful:
(a/go-loop []
(when-let [v (a/<! in-chan)] ; 1
(do-something v) ; 2
(recur))) ; 3
The use of
when-letensures that the loop will terminate if in-chan is closed.Often,
do-somethingwill involve putting to another channel.Don’t forget to keep looping!
Mapping and Filtering
Writing components that map or filter components is straightforward, using the above pattern:
(defn mapc [f in-chan out-chan]
(go-loop []
(when-let [v (a/<! in-chan)]
(a/>! out-chan (f v))))
(defn filterc [pred in-chan out-chan]
(go-loop []
(when-let [v (a/<! in-chan)]
(if (pred v)
(a/>! out-chan v))
(recur))))
However, you should generally prefer to express mapping and filtering operations as
transducers for the sake of resource use and brevity. If necessary, you can
use pipe to help with this:
(defn mapc [f in-chan]
(a/pipe in-chan (a/chan 0 (map f))))
; Or, for free parallelization, use pipeline (here with a thread pool of size 4)
(defn mapc-fast [f in-chan]
(let [out-chan (a/chan)]
(a/pipeline 4 out-chan (map f) in-chan)
out-chan))
Aggregation
Aggregations are necessarily stateful, so we’ll need a way to store that state. An easy
way to do this is to update that state via go-loop:
(defn count-occurrances
"Given a channel that streams words, emit a map of word to count over
a given window size"
[window-size word-chan]
(let [out-chan (a/chan)]
(a/go-loop [ii 0 counts {}]
(if (>= ii window-size)
(do
(a/>! out-chan counts)
(recur 0 {}))
(if-let [word (a/<! word-chan)]
(recur (inc ii) (update counts word (fnil inc 0)))
(a/close! out-chan))))
out-chan))
Components
To manage all those channels and processes, I’ve found it helpful to use Components. Component components describe long-running processes with resources that must be opened and closed, which accurately describes typical go loops and channels. Actually, I’ve found it helpful to use Component to structure most Clojure software I write; the restrictions imposed by this design tend to guide me towards writing more general components and less interconnected and coupled systems.
Components are plain clojure records that implement Lifecycle. Use the record fields to store configuration, references to provided components and/or resources that must be opened, exposed, and closed.
In this case, our components will consist of a channel plus a process. The components will store channel references, and other channels that depend on them can take from those channels and use them in their own processing.
Here’s an example source component:
(require '[com.stuartsierra.component :as component])
(defrecord LineStream [conf out-chan]
component/Lifecycle
(start [{{:keys [filename]} :conf :as this}]
(assoc this :out-chan (line-chan filename)))
(stop [{:keys [out-chan] :as this}]
(a/close! out-chan)
(dissoc this :out-chan)))
Note the reuse of the line-chan function from earlier. This is actually the only
service that requires closing; consumers are written such that their channels will close
when the input channel is closed.
Also, if this is starting to smell like an overengineered word count example, you’re completely right. Here are the other components (both of the xform type, as above):
(defrecord WordStream [conf line-stream out-mult]
component/Lifecycle
(start [{line-stream :line-stream :as this}]
(let [xform (comp (map clojure.string/lower-case)
(mapcat #(clojure.string/split % #"\s")))
out-chan (a/chan)]
(a/pipeline 4 out-chan xform (:out-chan line-stream))
;; Use a mult to support multiple consumers
(assoc this :out-mult (a/mult out-chan))))
; No need to close chan, since a/pipeline will close it
(stop [this] (dissoc this :out-mult)))
(defrecord WordCount [conf word-stream out-chan]
component/Lifecycle
(start [{{:keys [window-size buf-or-n]
:or {buf-or-n 10}} :conf
word-stream :word-stream
:as this}]
(let [in-chan (a/tap (:out-mult word-stream) (a/chan))]
(assoc this :out-chan (count-occurances window-size in-chan))))
(stop [this] (dissoc this :out-chan)))
Defining a system
Once defined, these components can be assembled into a system that can be started and stopped as a whole:
(defn mk-system [filename]
(component/system-map
:line-stream (->LineStream {:filename filename} nil)
:word-stream (component/using (->WordStream {} nil nil)
[:line-stream])
:word-count (component/using (->WordCount {:window-size 10000} nil nil)
[:word-stream])))
For debugging: the system map can be stored and the word-count output channel accessed to get the results.
(defn run []
(component/start (mk-system "mobydick.txt")))
(comment
; Repl-only stuff goes here
; Start the system
(def system (run))
; Check that words are being correctly produced
(a/<!! (-> system :word-stream :out-mult (a/tap (a/promise-chan))))
; Get counts
(a/<!! (-> system :word-count :out-chan))
; Stop the system
(component/stop system)
)
I have several applications presently running on this general architecture, and I’ve been surprised at just how rock-solid they’ve been.
I think my favorite thing about this design is the ease with which it can be remixed, refactored, and repurposed. Components can be changed and rewritten without requiring major changes to other parts of your program.
Since core.async channels are such a general tool, it’s also easy to adapt the channels connecting the components to add additional capabilities. To name one example: Kinsky is a Kafka library that provides a core.async channel interface; you barely have to change a thing to add a persistent, distributed, ultra-high-throughput message log to your system.
That’s it! I hope you learned something!